
On the similarity of symbol frequency distributions with heavy tails
Published:
M. Gerlach, F. Font-Clos, E. G. Altmann, Phys. Rev. X 6 021009
Download PDF here
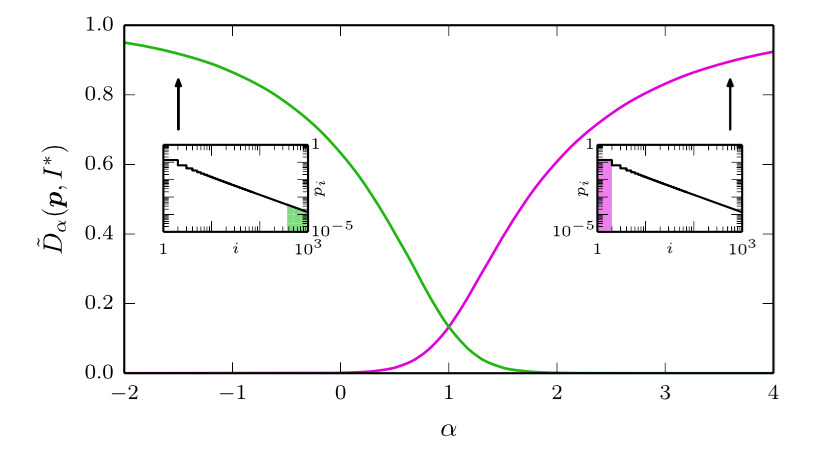
Abstract: Quantifying the similarity between symbolic sequences is a traditional problem in information theory which requires comparing the frequencies of symbols in different sequences. In numerous modern applications, ranging from DNA over music to texts, the distribution of symbol frequencies is characterized by heavy-tailed distributions (e.g., Zipf’s law). The large number of low-frequency symbols in these distributions poses major difficulties to the estimation of the similarity between sequences; e.g., they hinder an accurate finite-size estimation of entropies. Here, we show analytically how the systematic (bias) and statistical (fluctuations) errors in these estimations depend on the sample size N and on the exponent γ of the heavy-tailed distribution. Our results are valid for the Shannon entropy (α = 1), its corresponding similarity measures (e.g., the Jensen-Shanon divergence), and also for measures based on the generalized entropy of order α. For small α’s, including α = 1, the errors decay slower than the 1/N decay observed in short-tailed distributions. For α larger than a critical value α∗ = 1 + 1 / γ ≤ 2, the 1 / N decay is recovered. We show the practical significance of our results by quantifying the evolution of the English language over the last two centuries using a complete α spectrum of measures. We find that frequent words change more slowly than less frequent words and that α = 2 provides the most robust measure to quantify language change.