
A standardized Project Gutenberg corpus for statistical analysis of natural language and quantitative linguistics
Published:
M. Gerlach, F. Font-Clos, A standardized Project Gutenberg corpus for statistical analysis of natural language and quantitative linguistics, arXiv:1812.08092
Download PDF here
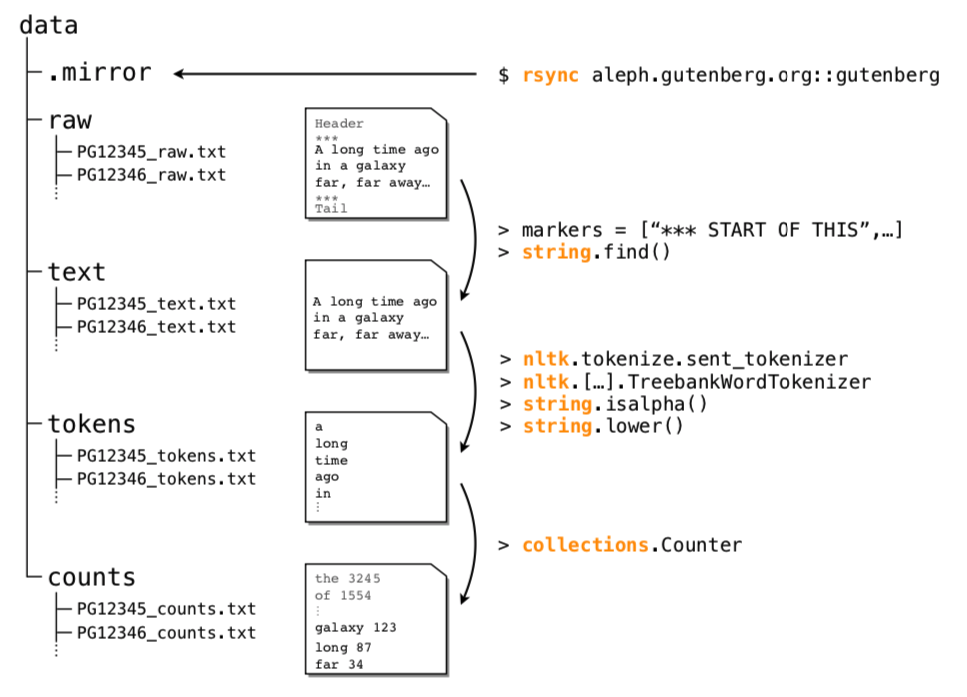
Abstract: We present the Standardized Project Gutenberg Corpus (SPGC), an open science approach to a curated version of the complete PG data containing more than 50,000 books and more than 3 × 10^9 word-tokens. Using different sources of annotated metadata, we not only provide a broad characterization of the content of PG, but also show different examples highlighting the potential of SPGC for investigating language variability across time, subjects, and authors. We publish our methodology in detail, the code to download and process the data, as well as the obtained corpus itself.